Build an MTH5 and Operate the Aurora Pipeline¶
This notebook pulls MT miniSEED data from the IRIS Dataselect web service to produce an MTH5 file, and then process the time series to create transfer function outputs.
It outlines the process of making an MTH5 file, generating a processing configuration object, and running the Aurora processor.
Aurora must be installed to run the notebook. Installation instructions are here. This will also install mth5, mt_metadata and mtpy-v2.
Flow of this notebook¶
Section 1: Construct a table of the data that will be accessed(in future this process may be automated via Earthscope’s data availability tools). The table is then used to build an MTH5 archive.
Section 2: The metadata and the data are accessed and used to process the data and generate transfer functions.
[1]:
# # Uncomment while developing
# %load_ext autoreload
# %autoreload 2
[2]:
# Required imports for the program.
from pathlib import Path
import pandas as pd
import warnings
from mth5 import mth5, timeseries
from mth5.clients.fdsn import FDSN
from mth5.clients.make_mth5 import MakeMTH5
from mth5.utils.helpers import initialize_mth5
from mt_metadata.utils.mttime import get_now_utc, MTime
from aurora.config import BANDS_DEFAULT_FILE
from aurora.config.config_creator import ConfigCreator
from aurora.pipelines.process_mth5 import process_mth5
from mth5.processing import RunSummary, KernelDataset
warnings.filterwarnings('ignore')
1. Build an MTH5 file from Earthscope archives¶
If you have already built an MTH5 you can skip this section
Set path so MTH5 file builds to current working directory.
[3]:
default_path = Path().cwd()
default_path
[3]:
PosixPath('/home/kkappler/software/irismt/aurora/docs/examples')
Select mth5 file version
[4]:
# mth5_version = '0.1.0'
mth5_version = '0.2.0'
[5]:
# Initalize an FDSN object to access column names for request df
fdsn_obj = FDSN()
1A: Specify the data to access from IRIS¶
Note that here we explicitly prescribe the data, but this dataframe could be built from IRIS data availability tools in a programatic way
[6]:
# Generate data frame of FDSN Network, Station, Location, Channel, Startime, Endtime codes of interest
station_id = "CAS04"
CAS04LQE = ['8P', station_id, '', 'LQE', '2020-06-02T19:00:00', '2020-07-13T19:00:00']
CAS04LQN = ['8P', station_id, '', 'LQN', '2020-06-02T19:00:00', '2020-07-13T19:00:00']
CAS04BFE = ['8P', station_id, '', 'LFE', '2020-06-02T19:00:00', '2020-07-13T19:00:00']
CAS04BFN = ['8P', station_id, '', 'LFN', '2020-06-02T19:00:00', '2020-07-13T19:00:00']
CAS04BFZ = ['8P', station_id, '', 'LFZ', '2020-06-02T19:00:00', '2020-07-13T19:00:00']
request_list = [CAS04LQE, CAS04LQN, CAS04BFE, CAS04BFN, CAS04BFZ]
# Turn list into dataframe
request_df = pd.DataFrame(request_list, columns=fdsn_obj.request_columns)
# Note that the file that will be build
h5_basename = f"8P_{station_id}.h5"
print(f"The MTH5 file will be named (automatically) based on the network and station: {h5_basename}")
The MTH5 file will be named (automatically) based on the network and station: 8P_CAS04.h5
[7]:
# Inspect the dataframe
request_df
[7]:
| network | station | location | channel | start | end | |
|---|---|---|---|---|---|---|
| 0 | 8P | CAS04 | LQE | 2020-06-02T19:00:00 | 2020-07-13T19:00:00 | |
| 1 | 8P | CAS04 | LQN | 2020-06-02T19:00:00 | 2020-07-13T19:00:00 | |
| 2 | 8P | CAS04 | LFE | 2020-06-02T19:00:00 | 2020-07-13T19:00:00 | |
| 3 | 8P | CAS04 | LFN | 2020-06-02T19:00:00 | 2020-07-13T19:00:00 | |
| 4 | 8P | CAS04 | LFZ | 2020-06-02T19:00:00 | 2020-07-13T19:00:00 |
[8]:
# Request the inventory information from IRIS
inventory = fdsn_obj.get_inventory_from_df(request_df, data=False)
[9]:
# Inspect the inventory
inventory
[9]:
(Inventory created at 2025-07-12T00:38:45.505865Z
Created by: ObsPy 1.4.1
https://www.obspy.org
Sending institution: MTH5
Contains:
Networks (1):
8P
Stations (1):
8P.CAS04 (Corral Hollow, CA, USA)
Channels (8):
8P.CAS04..LFZ, 8P.CAS04..LFN, 8P.CAS04..LFE, 8P.CAS04..LQN (2x),
8P.CAS04..LQE (3x),
0 Trace(s) in Stream:
)
Builds an MTH5 file from the user defined database.
With the mth5 object set, we are ready to actually request the data from the fdsn client (IRIS) and save it to an MTH5 file. This process builds an MTH5 file and can take some time depending on how much data is requested.
Note: interact keeps the MTH5 open after it is done building
[10]:
mth5_path = MakeMTH5.from_fdsn_client(request_df)
2025-07-11T17:38:55.199698-0700 | INFO | mt_metadata.timeseries.filters.obspy_stages | create_filter_from_stage | Converting PoleZerosResponseStage electric_si_units to a CoefficientFilter.
2025-07-11T17:38:55.202648-0700 | INFO | mt_metadata.timeseries.filters.obspy_stages | create_filter_from_stage | Converting PoleZerosResponseStage electric_dipole_92.000 to a CoefficientFilter.
2025-07-11T17:38:55.221132-0700 | INFO | mt_metadata.timeseries.filters.obspy_stages | create_filter_from_stage | Converting PoleZerosResponseStage electric_si_units to a CoefficientFilter.
2025-07-11T17:38:55.224140-0700 | INFO | mt_metadata.timeseries.filters.obspy_stages | create_filter_from_stage | Converting PoleZerosResponseStage electric_dipole_92.000 to a CoefficientFilter.
2025-07-11T17:38:55.240748-0700 | INFO | mt_metadata.timeseries.filters.obspy_stages | create_filter_from_stage | Converting PoleZerosResponseStage electric_si_units to a CoefficientFilter.
2025-07-11T17:38:55.245410-0700 | INFO | mt_metadata.timeseries.filters.obspy_stages | create_filter_from_stage | Converting PoleZerosResponseStage electric_dipole_92.000 to a CoefficientFilter.
2025-07-11T17:38:55.264651-0700 | INFO | mt_metadata.timeseries.filters.obspy_stages | create_filter_from_stage | Converting PoleZerosResponseStage electric_si_units to a CoefficientFilter.
2025-07-11T17:38:55.267511-0700 | INFO | mt_metadata.timeseries.filters.obspy_stages | create_filter_from_stage | Converting PoleZerosResponseStage electric_dipole_92.000 to a CoefficientFilter.
2025-07-11T17:38:55.288150-0700 | INFO | mt_metadata.timeseries.filters.obspy_stages | create_filter_from_stage | Converting PoleZerosResponseStage electric_si_units to a CoefficientFilter.
2025-07-11T17:38:55.293274-0700 | INFO | mt_metadata.timeseries.filters.obspy_stages | create_filter_from_stage | Converting PoleZerosResponseStage electric_dipole_92.000 to a CoefficientFilter.
2025-07-11T17:38:55.352578-0700 | WARNING | mth5.mth5 | open_mth5 | 8P_CAS04.h5 will be overwritten in 'w' mode
2025-07-11T17:38:55.363350-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for MasterSurvey, skipping from_dict.
2025-07-11T17:38:55.364174-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for Reports, skipping from_dict.
2025-07-11T17:38:55.650559-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for Standards, skipping from_dict.
2025-07-11T17:38:55.655107-0700 | INFO | mth5.mth5 | _initialize_file | Initialized MTH5 0.2.0 file /home/kkappler/software/irismt/aurora/docs/examples/8P_CAS04.h5 in mode w
2025-07-11T17:38:55.661714-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for MasterStation, skipping from_dict.
2025-07-11T17:38:55.663257-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for Reports, skipping from_dict.
2025-07-11T17:38:55.665236-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for Filters, skipping from_dict.
2025-07-11T17:38:55.923083-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for Standards, skipping from_dict.
2025-07-11T17:38:55.934927-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for Station, skipping from_dict.
2025-07-11T17:38:55.943460-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for TransferFunctions, skipping from_dict.
2025-07-11T17:38:55.944362-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for MasterFC, skipping from_dict.
2025-07-11T17:38:55.945333-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for MasterFeatures, skipping from_dict.
2025-07-11T17:38:55.950347-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for Run, skipping from_dict.
2025-07-11T17:38:55.988470-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for Run, skipping from_dict.
2025-07-11T17:38:56.025298-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for Run, skipping from_dict.
2025-07-11T17:38:56.063017-0700 | WARNING | mth5.groups.base | read_metadata | No metadata found for Run, skipping from_dict.
2025-07-11T17:38:56.644677-0700 | WARNING | mth5.clients.fdsn | wrangle_runs_into_containers | More or less runs have been requested by the user than are defined in the metadata. Runs will be defined but only the requested run extents contain time series data based on the users request.
2025-07-11T17:38:56.651064-0700 | INFO | mth5.groups.base | _add_group | RunGroup Features already exists, returning existing group.
2025-07-11T17:38:56.659210-0700 | INFO | mth5.groups.base | _add_group | RunGroup a already exists, returning existing group.
2025-07-11T17:38:56.784591-0700 | WARNING | mth5.timeseries.run_ts | validate_metadata | start time of dataset 2020-06-02T19:00:00+00:00 does not match metadata start 2020-06-02T18:41:43+00:00 updating metatdata value to 2020-06-02T19:00:00+00:00
2025-07-11T17:38:56.905979-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id a. Setting to ch.run_metadata.id to a
2025-07-11T17:38:57.062055-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id a. Setting to ch.run_metadata.id to a
2025-07-11T17:38:57.213695-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id a. Setting to ch.run_metadata.id to a
2025-07-11T17:38:57.366738-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id a. Setting to ch.run_metadata.id to a
2025-07-11T17:38:57.518731-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id a. Setting to ch.run_metadata.id to a
2025-07-11T17:38:57.580181-0700 | INFO | mth5.groups.base | _add_group | RunGroup Features already exists, returning existing group.
2025-07-11T17:38:57.585893-0700 | INFO | mth5.groups.base | _add_group | RunGroup a already exists, returning existing group.
2025-07-11T17:38:57.615171-0700 | INFO | mth5.groups.base | _add_group | RunGroup b already exists, returning existing group.
2025-07-11T17:38:58.281363-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id b. Setting to ch.run_metadata.id to b
2025-07-11T17:38:58.433788-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id b. Setting to ch.run_metadata.id to b
2025-07-11T17:38:58.594554-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id b. Setting to ch.run_metadata.id to b
2025-07-11T17:38:58.745508-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id b. Setting to ch.run_metadata.id to b
2025-07-11T17:38:58.902618-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id b. Setting to ch.run_metadata.id to b
2025-07-11T17:38:58.964310-0700 | INFO | mth5.groups.base | _add_group | RunGroup Features already exists, returning existing group.
2025-07-11T17:38:58.970111-0700 | INFO | mth5.groups.base | _add_group | RunGroup a already exists, returning existing group.
2025-07-11T17:38:58.998062-0700 | INFO | mth5.groups.base | _add_group | RunGroup b already exists, returning existing group.
2025-07-11T17:38:59.022624-0700 | INFO | mth5.groups.base | _add_group | RunGroup c already exists, returning existing group.
2025-07-11T17:39:00.177648-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id c. Setting to ch.run_metadata.id to c
2025-07-11T17:39:00.367221-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id c. Setting to ch.run_metadata.id to c
2025-07-11T17:39:00.561857-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id c. Setting to ch.run_metadata.id to c
2025-07-11T17:39:00.727201-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id c. Setting to ch.run_metadata.id to c
2025-07-11T17:39:00.894645-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id c. Setting to ch.run_metadata.id to c
2025-07-11T17:39:00.962280-0700 | INFO | mth5.groups.base | _add_group | RunGroup Features already exists, returning existing group.
2025-07-11T17:39:00.968133-0700 | INFO | mth5.groups.base | _add_group | RunGroup a already exists, returning existing group.
2025-07-11T17:39:00.995525-0700 | INFO | mth5.groups.base | _add_group | RunGroup b already exists, returning existing group.
2025-07-11T17:39:01.022895-0700 | INFO | mth5.groups.base | _add_group | RunGroup c already exists, returning existing group.
2025-07-11T17:39:01.052501-0700 | INFO | mth5.groups.base | _add_group | RunGroup d already exists, returning existing group.
2025-07-11T17:39:01.688527-0700 | WARNING | mth5.timeseries.run_ts | validate_metadata | end time of dataset 2020-07-13T19:00:00+00:00 does not match metadata end 2020-07-13T21:46:12+00:00 updating metatdata value to 2020-07-13T19:00:00+00:00
2025-07-11T17:39:01.882289-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id d. Setting to ch.run_metadata.id to d
2025-07-11T17:39:02.087284-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id d. Setting to ch.run_metadata.id to d
2025-07-11T17:39:02.270654-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id d. Setting to ch.run_metadata.id to d
2025-07-11T17:39:02.420140-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id d. Setting to ch.run_metadata.id to d
2025-07-11T17:39:02.574915-0700 | WARNING | mth5.groups.run | from_runts | Channel run.id sr1_001 != group run.id d. Setting to ch.run_metadata.id to d
2025-07-11T17:39:02.750420-0700 | INFO | mth5.mth5 | close_mth5 | Flushing and closing /home/kkappler/software/irismt/aurora/docs/examples/8P_CAS04.h5
1B: Examine and Update the MTH5 object¶
With the open MTH5 Object, we can start to examine what is in it. For example, retrieve the filename and file_version. You can additionally do things such as getting the station information and edit it by setting a new value, in this case the declination model.
[11]:
mth5_object = initialize_mth5(mth5_path)
[12]:
mth5_object.file_version
[12]:
'0.2.0'
1C: Optionally Update Metdata:¶
[13]:
# Edit and update the MTH5 metadata
s = mth5_object.get_station(station_id, survey="CONUS_South")
print(s.metadata.location.declination.model)
s.metadata.location.declination.model = 'IGRF'
print(s.metadata.location.declination.model)
s.write_metadata() # writes to file mth5_filename
IGRF-13
IGRF
[14]:
# Print some info about the mth5
mth5_filename = mth5_object.filename
version = mth5_object.file_version
print(f" Filename: {mth5_filename} \n Version: {version}")
Filename: /home/kkappler/software/irismt/aurora/docs/examples/8P_CAS04.h5
Version: 0.2.0
[15]:
# Get the available stations and runs from the MTH5 object
mth5_object.channel_summary.summarize()
ch_summary = mth5_object.channel_summary.to_dataframe()
2: Process Data¶
If MTH5 file already exists you can start here if you dont want to execute the previous code to get data again.
[16]:
interact = False
if interact:
pass
else:
h5_basename = f"8P_{station_id}.h5"
h5_path = default_path.joinpath(h5_basename)
mth5_object = initialize_mth5(h5_path, mode="a", file_version=mth5_version)
ch_summary = mth5_object.channel_summary.to_dataframe()
Generate an Aurora Configuration file using MTH5 as an input¶
Up to this point, we have used mth5 and mt_metadata, but haven’t yet used aurora. So we will use the MTH5 that we just created (and examined and updated) as input into Aurora.
Channel Summary¶
This is a very useful datastructure inside the mth5. It acts basically like an index of available data at the channel-run level, i.e. there is one row for every contiguous chunk of time-series recorded by an electric dipole or magnetometer
[17]:
ch_summary
[17]:
| survey | station | run | latitude | longitude | elevation | component | start | end | n_samples | sample_rate | measurement_type | azimuth | tilt | units | has_data | hdf5_reference | run_hdf5_reference | station_hdf5_reference | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CONUS South | CAS04 | a | 37.633351 | -121.468382 | 335.261765 | ex | 2020-06-02 19:00:00+00:00 | 2020-06-02 22:07:46+00:00 | 11267 | 1.0 | electric | 13.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 1 | CONUS South | CAS04 | a | 37.633351 | -121.468382 | 335.261765 | ey | 2020-06-02 19:00:00+00:00 | 2020-06-02 22:07:46+00:00 | 11267 | 1.0 | electric | 103.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 2 | CONUS South | CAS04 | a | 37.633351 | -121.468382 | 335.261765 | hx | 2020-06-02 19:00:00+00:00 | 2020-06-02 22:07:46+00:00 | 11267 | 1.0 | magnetic | 13.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 3 | CONUS South | CAS04 | a | 37.633351 | -121.468382 | 335.261765 | hy | 2020-06-02 19:00:00+00:00 | 2020-06-02 22:07:46+00:00 | 11267 | 1.0 | magnetic | 103.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 4 | CONUS South | CAS04 | a | 37.633351 | -121.468382 | 335.261765 | hz | 2020-06-02 19:00:00+00:00 | 2020-06-02 22:07:46+00:00 | 11267 | 1.0 | magnetic | 0.0 | 90.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 5 | CONUS South | CAS04 | b | 37.633351 | -121.468382 | 335.261765 | ex | 2020-06-02 22:24:55+00:00 | 2020-06-12 17:52:23+00:00 | 847649 | 1.0 | electric | 13.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 6 | CONUS South | CAS04 | b | 37.633351 | -121.468382 | 335.261765 | ey | 2020-06-02 22:24:55+00:00 | 2020-06-12 17:52:23+00:00 | 847649 | 1.0 | electric | 103.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 7 | CONUS South | CAS04 | b | 37.633351 | -121.468382 | 335.261765 | hx | 2020-06-02 22:24:55+00:00 | 2020-06-12 17:52:23+00:00 | 847649 | 1.0 | magnetic | 13.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 8 | CONUS South | CAS04 | b | 37.633351 | -121.468382 | 335.261765 | hy | 2020-06-02 22:24:55+00:00 | 2020-06-12 17:52:23+00:00 | 847649 | 1.0 | magnetic | 103.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 9 | CONUS South | CAS04 | b | 37.633351 | -121.468382 | 335.261765 | hz | 2020-06-02 22:24:55+00:00 | 2020-06-12 17:52:23+00:00 | 847649 | 1.0 | magnetic | 0.0 | 90.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 10 | CONUS South | CAS04 | c | 37.633351 | -121.468382 | 335.261765 | ex | 2020-06-12 18:32:17+00:00 | 2020-07-01 17:32:59+00:00 | 1638043 | 1.0 | electric | 13.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 11 | CONUS South | CAS04 | c | 37.633351 | -121.468382 | 335.261765 | ey | 2020-06-12 18:32:17+00:00 | 2020-07-01 17:32:59+00:00 | 1638043 | 1.0 | electric | 103.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 12 | CONUS South | CAS04 | c | 37.633351 | -121.468382 | 335.261765 | hx | 2020-06-12 18:32:17+00:00 | 2020-07-01 17:32:59+00:00 | 1638043 | 1.0 | magnetic | 13.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 13 | CONUS South | CAS04 | c | 37.633351 | -121.468382 | 335.261765 | hy | 2020-06-12 18:32:17+00:00 | 2020-07-01 17:32:59+00:00 | 1638043 | 1.0 | magnetic | 103.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 14 | CONUS South | CAS04 | c | 37.633351 | -121.468382 | 335.261765 | hz | 2020-06-12 18:32:17+00:00 | 2020-07-01 17:32:59+00:00 | 1638043 | 1.0 | magnetic | 0.0 | 90.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 15 | CONUS South | CAS04 | d | 37.633351 | -121.468382 | 335.261765 | ex | 2020-07-01 19:36:55+00:00 | 2020-07-13 19:00:00+00:00 | 1034586 | 1.0 | electric | 13.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 16 | CONUS South | CAS04 | d | 37.633351 | -121.468382 | 335.261765 | ey | 2020-07-01 19:36:55+00:00 | 2020-07-13 19:00:00+00:00 | 1034586 | 1.0 | electric | 103.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 17 | CONUS South | CAS04 | d | 37.633351 | -121.468382 | 335.261765 | hx | 2020-07-01 19:36:55+00:00 | 2020-07-13 19:00:00+00:00 | 1034586 | 1.0 | magnetic | 13.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 18 | CONUS South | CAS04 | d | 37.633351 | -121.468382 | 335.261765 | hy | 2020-07-01 19:36:55+00:00 | 2020-07-13 19:00:00+00:00 | 1034586 | 1.0 | magnetic | 103.2 | 0.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
| 19 | CONUS South | CAS04 | d | 37.633351 | -121.468382 | 335.261765 | hz | 2020-07-01 19:36:55+00:00 | 2020-07-13 19:00:00+00:00 | 1034586 | 1.0 | magnetic | 0.0 | 90.0 | digital counts | True | <HDF5 object reference> | <HDF5 object reference> | <HDF5 object reference> |
The Channel summary has a lot of uses, below we use it to check if the data have mixed sample rates, and to get a list of available stations
[18]:
available_runs = ch_summary.run.unique()
sr = ch_summary.sample_rate.unique()
if len(sr) != 1:
print('Only one sample rate per run is available')
available_stations = ch_summary.station.unique()
print(f"Available stations: {available_stations}")
Available stations: ['CAS04']
Run Summary¶
A cousin of the channel summary is the Run Summary. This is a condensed version of the channel summary, with one row per continuous acquistion run at a station.
The run summary can be accessed from an open mth5 object, or from an iterable of h5 paths as in the example below
[19]:
mth5_run_summary = RunSummary()
h5_path = default_path.joinpath(h5_basename)
mth5_run_summary.from_mth5s([h5_path,])
run_summary = mth5_run_summary.clone()
run_summary.df
2025-07-11T17:39:03.857897-0700 | INFO | mth5.mth5 | close_mth5 | Flushing and closing /home/kkappler/software/irismt/aurora/docs/examples/8P_CAS04.h5
[19]:
| channel_scale_factors | duration | end | has_data | input_channels | mth5_path | n_samples | output_channels | run | sample_rate | start | station | survey | run_hdf5_reference | station_hdf5_reference | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | {'ex': 1.0, 'ey': 1.0, 'hx': 1.0, 'hy': 1.0, '... | 11266.0 | 2020-06-02 22:07:46+00:00 | True | [hx, hy] | /home/kkappler/software/irismt/aurora/docs/exa... | 11267 | [ex, ey, hz] | a | 1.0 | 2020-06-02 19:00:00+00:00 | CAS04 | CONUS South | <HDF5 object reference> | <HDF5 object reference> |
| 1 | {'ex': 1.0, 'ey': 1.0, 'hx': 1.0, 'hy': 1.0, '... | 847648.0 | 2020-06-12 17:52:23+00:00 | True | [hx, hy] | /home/kkappler/software/irismt/aurora/docs/exa... | 847649 | [ex, ey, hz] | b | 1.0 | 2020-06-02 22:24:55+00:00 | CAS04 | CONUS South | <HDF5 object reference> | <HDF5 object reference> |
| 2 | {'ex': 1.0, 'ey': 1.0, 'hx': 1.0, 'hy': 1.0, '... | 1638042.0 | 2020-07-01 17:32:59+00:00 | True | [hx, hy] | /home/kkappler/software/irismt/aurora/docs/exa... | 1638043 | [ex, ey, hz] | c | 1.0 | 2020-06-12 18:32:17+00:00 | CAS04 | CONUS South | <HDF5 object reference> | <HDF5 object reference> |
| 3 | {'ex': 1.0, 'ey': 1.0, 'hx': 1.0, 'hy': 1.0, '... | 1034585.0 | 2020-07-13 19:00:00+00:00 | True | [hx, hy] | /home/kkappler/software/irismt/aurora/docs/exa... | 1034586 | [ex, ey, hz] | d | 1.0 | 2020-07-01 19:36:55+00:00 | CAS04 | CONUS South | <HDF5 object reference> | <HDF5 object reference> |
Now we have a dataframe of the available runs to process from the MTH5
Sometimes we just want to look at the survey, station, run, and time intervals we can for that we can call mini_summary
[20]:
run_summary.mini_summary
[20]:
| survey | station | run | start | end | duration | |
|---|---|---|---|---|---|---|
| 0 | CONUS South | CAS04 | a | 2020-06-02 19:00:00+00:00 | 2020-06-02 22:07:46+00:00 | 11266.0 |
| 1 | CONUS South | CAS04 | b | 2020-06-02 22:24:55+00:00 | 2020-06-12 17:52:23+00:00 | 847648.0 |
| 2 | CONUS South | CAS04 | c | 2020-06-12 18:32:17+00:00 | 2020-07-01 17:32:59+00:00 | 1638042.0 |
| 3 | CONUS South | CAS04 | d | 2020-07-01 19:36:55+00:00 | 2020-07-13 19:00:00+00:00 | 1034585.0 |
But here are the columns in the run summary
[21]:
run_summary.df.columns
[21]:
Index(['channel_scale_factors', 'duration', 'end', 'has_data',
'input_channels', 'mth5_path', 'n_samples', 'output_channels', 'run',
'sample_rate', 'start', 'station', 'survey', 'run_hdf5_reference',
'station_hdf5_reference'],
dtype='object')
Make your own mini summary by choosing columns
[22]:
coverage_short_list_columns = ["survey", 'station', 'run', 'start', 'end', ]
run_summary.df[coverage_short_list_columns]
[22]:
| survey | station | run | start | end | |
|---|---|---|---|---|---|
| 0 | CONUS South | CAS04 | a | 2020-06-02 19:00:00+00:00 | 2020-06-02 22:07:46+00:00 |
| 1 | CONUS South | CAS04 | b | 2020-06-02 22:24:55+00:00 | 2020-06-12 17:52:23+00:00 |
| 2 | CONUS South | CAS04 | c | 2020-06-12 18:32:17+00:00 | 2020-07-01 17:32:59+00:00 |
| 3 | CONUS South | CAS04 | d | 2020-07-01 19:36:55+00:00 | 2020-07-13 19:00:00+00:00 |
Kernel Dataset¶
This is like a run summary, but for a single station or a pair of stations. It is used to specify the inputs to aurora processing.
It takes a run_summary and a station name, and optionally, a remote reference station name
It is made based on the available data in the MTH5 archive.
Syntax: kernel_dataset.from_run_summary(run_summary, local_station_id, reference_station_id)
By Default, all runs will be processed
To restrict to processing a single run, or a list of runs, we can either tell KernelDataset to keep or drop a station_run dictionary.
[23]:
kernel_dataset = KernelDataset()
kernel_dataset.from_run_summary(run_summary, station_id)
kernel_dataset.mini_summary
2025-07-11T17:39:03.929904-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column fc, adding and setting dtype to <class 'pandas._libs.missing.NAType'>.
2025-07-11T17:39:03.930634-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column remote, adding and setting dtype to <class 'bool'>.
2025-07-11T17:39:03.931502-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column run_dataarray, adding and setting dtype to <class 'NoneType'>.
2025-07-11T17:39:03.932238-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column stft, adding and setting dtype to <class 'NoneType'>.
2025-07-11T17:39:03.933350-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column mth5_obj, adding and setting dtype to <class 'NoneType'>.
[23]:
| survey | station | run | start | end | duration | |
|---|---|---|---|---|---|---|
| 0 | CONUS South | CAS04 | a | 2020-06-02 19:00:00+00:00 | 2020-06-02 22:07:46+00:00 | 11266.0 |
| 1 | CONUS South | CAS04 | b | 2020-06-02 22:24:55+00:00 | 2020-06-12 17:52:23+00:00 | 847648.0 |
| 2 | CONUS South | CAS04 | c | 2020-06-12 18:32:17+00:00 | 2020-07-01 17:32:59+00:00 | 1638042.0 |
| 3 | CONUS South | CAS04 | d | 2020-07-01 19:36:55+00:00 | 2020-07-13 19:00:00+00:00 | 1034585.0 |
Here is one way to select a single run:¶
[24]:
station_runs_dict = {}
station_runs_dict[station_id] = ["a", ]
keep_or_drop = "keep"
kernel_dataset.select_station_runs(station_runs_dict, keep_or_drop)
print(kernel_dataset.df[coverage_short_list_columns])
survey station run start end
0 CONUS South CAS04 a 2020-06-02 19:00:00+00:00 2020-06-02 22:07:46+00:00
To discard runs that are not very long¶
[25]:
kernel_dataset = KernelDataset()
kernel_dataset.from_run_summary(run_summary, station_id)
cutoff_duration_in_seconds = 15000
kernel_dataset.drop_runs_shorter_than(cutoff_duration_in_seconds)
kernel_dataset.df[coverage_short_list_columns]
2025-07-11T17:39:03.963827-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column fc, adding and setting dtype to <class 'pandas._libs.missing.NAType'>.
2025-07-11T17:39:03.964847-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column remote, adding and setting dtype to <class 'bool'>.
2025-07-11T17:39:03.965563-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column run_dataarray, adding and setting dtype to <class 'NoneType'>.
2025-07-11T17:39:03.966362-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column stft, adding and setting dtype to <class 'NoneType'>.
2025-07-11T17:39:03.967914-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column mth5_obj, adding and setting dtype to <class 'NoneType'>.
[25]:
| survey | station | run | start | end | |
|---|---|---|---|---|---|
| 0 | CONUS South | CAS04 | b | 2020-06-02 22:24:55+00:00 | 2020-06-12 17:52:23+00:00 |
| 1 | CONUS South | CAS04 | c | 2020-06-12 18:32:17+00:00 | 2020-07-01 17:32:59+00:00 |
| 2 | CONUS South | CAS04 | d | 2020-07-01 19:36:55+00:00 | 2020-07-13 19:00:00+00:00 |
Select only runs “b” & “d”¶
[26]:
kernel_dataset = KernelDataset()
kernel_dataset.from_run_summary(run_summary, "CAS04")
station_runs_dict = {}
station_runs_dict[station_id] = ["b","d"]
keep_or_drop = "keep"
kernel_dataset.select_station_runs(station_runs_dict, keep_or_drop)
kernel_dataset.df[coverage_short_list_columns]
2025-07-11T17:39:03.982055-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column fc, adding and setting dtype to <class 'pandas._libs.missing.NAType'>.
2025-07-11T17:39:03.984903-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column remote, adding and setting dtype to <class 'bool'>.
2025-07-11T17:39:03.987201-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column run_dataarray, adding and setting dtype to <class 'NoneType'>.
2025-07-11T17:39:03.989808-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column stft, adding and setting dtype to <class 'NoneType'>.
2025-07-11T17:39:03.991178-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column mth5_obj, adding and setting dtype to <class 'NoneType'>.
[26]:
| survey | station | run | start | end | |
|---|---|---|---|---|---|
| 0 | CONUS South | CAS04 | b | 2020-06-02 22:24:55+00:00 | 2020-06-12 17:52:23+00:00 |
| 1 | CONUS South | CAS04 | d | 2020-07-01 19:36:55+00:00 | 2020-07-13 19:00:00+00:00 |
The same result can be obtained by excluding runs a & c¶
[27]:
kernel_dataset = KernelDataset()
kernel_dataset.from_run_summary(run_summary, station_id)
station_runs_dict = {}
station_runs_dict[station_id] = ["a","c"]
keep_or_drop = "drop"
kernel_dataset.select_station_runs(station_runs_dict, keep_or_drop)
kernel_dataset.df[coverage_short_list_columns]
2025-07-11T17:39:04.008557-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column fc, adding and setting dtype to <class 'pandas._libs.missing.NAType'>.
2025-07-11T17:39:04.009698-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column remote, adding and setting dtype to <class 'bool'>.
2025-07-11T17:39:04.010545-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column run_dataarray, adding and setting dtype to <class 'NoneType'>.
2025-07-11T17:39:04.011360-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column stft, adding and setting dtype to <class 'NoneType'>.
2025-07-11T17:39:04.012052-0700 | INFO | mth5.processing.kernel_dataset | _add_columns | KernelDataset DataFrame needs column mth5_obj, adding and setting dtype to <class 'NoneType'>.
[27]:
| survey | station | run | start | end | |
|---|---|---|---|---|---|
| 0 | CONUS South | CAS04 | b | 2020-06-02 22:24:55+00:00 | 2020-06-12 17:52:23+00:00 |
| 1 | CONUS South | CAS04 | d | 2020-07-01 19:36:55+00:00 | 2020-07-13 19:00:00+00:00 |
To process only a segment of data¶
Say that you have weeks of data available, but you want to restrict the data processed to a subset. If it is one contiguous subset block, you can just modify the run_summary table as below. You should also update the duration column by calling kernel_dataset._add_duration_column() afterwards:
[28]:
# kernel_dataset.df["start"].iloc[0] += pd.Timedelta(days=5)
# kernel_dataset.df["start"].iloc[1] += pd.Timedelta(days=7)
# kernel_dataset._add_duration_column()
Exercise:¶
Print the kernel_dataset dataframe by calling
kernel_dataset.dfModify the start and end times, call _add_duration_column() and print it again.
You can also process the data with and without this change
Are the TFs different?
Make an aurora configuration file (and then save that json file.)
[29]:
cc = ConfigCreator()
config = cc.create_from_kernel_dataset(kernel_dataset,
emtf_band_file=BANDS_DEFAULT_FILE,)
[30]:
for decimation in config.decimations:
# decimation.output_channels = ["ex", "ey"]
decimation.estimator.engine = "RME"
Take a look at the config:
[31]:
config
[31]:
{
"processing": {
"band_setup_file": "/home/kkappler/software/irismt/aurora/aurora/config/emtf_band_setup/bs_test.cfg",
"band_specification_style": "EMTF",
"channel_nomenclature.ex": "ex",
"channel_nomenclature.ey": "ey",
"channel_nomenclature.hx": "hx",
"channel_nomenclature.hy": "hy",
"channel_nomenclature.hz": "hz",
"decimations": [
{
"decimation_level": {
"bands": [
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 0,
"frequency_max": 0.23828125,
"frequency_min": 0.19140625,
"index_max": 30,
"index_min": 25
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 0,
"frequency_max": 0.19140625,
"frequency_min": 0.15234375,
"index_max": 24,
"index_min": 20
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 0,
"frequency_max": 0.15234375,
"frequency_min": 0.12109375,
"index_max": 19,
"index_min": 16
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 0,
"frequency_max": 0.12109375,
"frequency_min": 0.09765625,
"index_max": 15,
"index_min": 13
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 0,
"frequency_max": 0.09765625,
"frequency_min": 0.07421875,
"index_max": 12,
"index_min": 10
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 0,
"frequency_max": 0.07421875,
"frequency_min": 0.05859375,
"index_max": 9,
"index_min": 8
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 0,
"frequency_max": 0.05859375,
"frequency_min": 0.04296875,
"index_max": 7,
"index_min": 6
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 0,
"frequency_max": 0.04296875,
"frequency_min": 0.03515625,
"index_max": 5,
"index_min": 5
}
}
],
"channel_weight_specs": [],
"decimation.anti_alias_filter": "default",
"decimation.factor": 1.0,
"decimation.level": 0,
"decimation.method": "default",
"decimation.sample_rate": 1.0,
"estimator.engine": "RME",
"estimator.estimate_per_channel": true,
"input_channels": [
"hx",
"hy"
],
"output_channels": [
"ex",
"ey",
"hz"
],
"reference_channels": [
"hx",
"hy"
],
"regression.max_iterations": 10,
"regression.max_redescending_iterations": 2,
"regression.minimum_cycles": 10,
"regression.r0": 1.5,
"regression.tolerance": 0.005,
"regression.u0": 2.8,
"regression.verbosity": 0,
"save_fcs": false,
"stft.harmonic_indices": [
-1
],
"stft.method": "fft",
"stft.min_num_stft_windows": 2,
"stft.per_window_detrend_type": "linear",
"stft.pre_fft_detrend_type": "linear",
"stft.prewhitening_type": "first difference",
"stft.recoloring": true,
"stft.window.clock_zero_type": "ignore",
"stft.window.normalized": true,
"stft.window.num_samples": 128,
"stft.window.overlap": 32,
"stft.window.type": "boxcar"
}
},
{
"decimation_level": {
"bands": [
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 1,
"frequency_max": 0.0341796875,
"frequency_min": 0.0263671875,
"index_max": 17,
"index_min": 14
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 1,
"frequency_max": 0.0263671875,
"frequency_min": 0.0205078125,
"index_max": 13,
"index_min": 11
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 1,
"frequency_max": 0.0205078125,
"frequency_min": 0.0166015625,
"index_max": 10,
"index_min": 9
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 1,
"frequency_max": 0.0166015625,
"frequency_min": 0.0126953125,
"index_max": 8,
"index_min": 7
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 1,
"frequency_max": 0.0126953125,
"frequency_min": 0.0107421875,
"index_max": 6,
"index_min": 6
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 1,
"frequency_max": 0.0107421875,
"frequency_min": 0.0087890625,
"index_max": 5,
"index_min": 5
}
}
],
"channel_weight_specs": [],
"decimation.anti_alias_filter": "default",
"decimation.factor": 4.0,
"decimation.level": 1,
"decimation.method": "default",
"decimation.sample_rate": 0.25,
"estimator.engine": "RME",
"estimator.estimate_per_channel": true,
"input_channels": [
"hx",
"hy"
],
"output_channels": [
"ex",
"ey",
"hz"
],
"reference_channels": [
"hx",
"hy"
],
"regression.max_iterations": 10,
"regression.max_redescending_iterations": 2,
"regression.minimum_cycles": 10,
"regression.r0": 1.5,
"regression.tolerance": 0.005,
"regression.u0": 2.8,
"regression.verbosity": 0,
"save_fcs": false,
"stft.harmonic_indices": [
-1
],
"stft.method": "fft",
"stft.min_num_stft_windows": 2,
"stft.per_window_detrend_type": "linear",
"stft.pre_fft_detrend_type": "linear",
"stft.prewhitening_type": "first difference",
"stft.recoloring": true,
"stft.window.clock_zero_type": "ignore",
"stft.window.normalized": true,
"stft.window.num_samples": 128,
"stft.window.overlap": 32,
"stft.window.type": "boxcar"
}
},
{
"decimation_level": {
"bands": [
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 2,
"frequency_max": 0.008544921875,
"frequency_min": 0.006591796875,
"index_max": 17,
"index_min": 14
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 2,
"frequency_max": 0.006591796875,
"frequency_min": 0.005126953125,
"index_max": 13,
"index_min": 11
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 2,
"frequency_max": 0.005126953125,
"frequency_min": 0.004150390625,
"index_max": 10,
"index_min": 9
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 2,
"frequency_max": 0.004150390625,
"frequency_min": 0.003173828125,
"index_max": 8,
"index_min": 7
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 2,
"frequency_max": 0.003173828125,
"frequency_min": 0.002685546875,
"index_max": 6,
"index_min": 6
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 2,
"frequency_max": 0.002685546875,
"frequency_min": 0.002197265625,
"index_max": 5,
"index_min": 5
}
}
],
"channel_weight_specs": [],
"decimation.anti_alias_filter": "default",
"decimation.factor": 4.0,
"decimation.level": 2,
"decimation.method": "default",
"decimation.sample_rate": 0.0625,
"estimator.engine": "RME",
"estimator.estimate_per_channel": true,
"input_channels": [
"hx",
"hy"
],
"output_channels": [
"ex",
"ey",
"hz"
],
"reference_channels": [
"hx",
"hy"
],
"regression.max_iterations": 10,
"regression.max_redescending_iterations": 2,
"regression.minimum_cycles": 10,
"regression.r0": 1.5,
"regression.tolerance": 0.005,
"regression.u0": 2.8,
"regression.verbosity": 0,
"save_fcs": false,
"stft.harmonic_indices": [
-1
],
"stft.method": "fft",
"stft.min_num_stft_windows": 2,
"stft.per_window_detrend_type": "linear",
"stft.pre_fft_detrend_type": "linear",
"stft.prewhitening_type": "first difference",
"stft.recoloring": true,
"stft.window.clock_zero_type": "ignore",
"stft.window.normalized": true,
"stft.window.num_samples": 128,
"stft.window.overlap": 32,
"stft.window.type": "boxcar"
}
},
{
"decimation_level": {
"bands": [
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 3,
"frequency_max": 0.00274658203125,
"frequency_min": 0.00213623046875,
"index_max": 22,
"index_min": 18
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 3,
"frequency_max": 0.00213623046875,
"frequency_min": 0.00164794921875,
"index_max": 17,
"index_min": 14
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 3,
"frequency_max": 0.00164794921875,
"frequency_min": 0.00115966796875,
"index_max": 13,
"index_min": 10
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 3,
"frequency_max": 0.00115966796875,
"frequency_min": 0.00079345703125,
"index_max": 9,
"index_min": 7
}
},
{
"band": {
"center_averaging_type": "geometric",
"closed": "left",
"decimation_level": 3,
"frequency_max": 0.00079345703125,
"frequency_min": 0.00054931640625,
"index_max": 6,
"index_min": 5
}
}
],
"channel_weight_specs": [],
"decimation.anti_alias_filter": "default",
"decimation.factor": 4.0,
"decimation.level": 3,
"decimation.method": "default",
"decimation.sample_rate": 0.015625,
"estimator.engine": "RME",
"estimator.estimate_per_channel": true,
"input_channels": [
"hx",
"hy"
],
"output_channels": [
"ex",
"ey",
"hz"
],
"reference_channels": [
"hx",
"hy"
],
"regression.max_iterations": 10,
"regression.max_redescending_iterations": 2,
"regression.minimum_cycles": 10,
"regression.r0": 1.5,
"regression.tolerance": 0.005,
"regression.u0": 2.8,
"regression.verbosity": 0,
"save_fcs": false,
"stft.harmonic_indices": [
-1
],
"stft.method": "fft",
"stft.min_num_stft_windows": 2,
"stft.per_window_detrend_type": "linear",
"stft.pre_fft_detrend_type": "linear",
"stft.prewhitening_type": "first difference",
"stft.recoloring": true,
"stft.window.clock_zero_type": "ignore",
"stft.window.normalized": true,
"stft.window.num_samples": 128,
"stft.window.overlap": 32,
"stft.window.type": "boxcar"
}
}
],
"id": "CAS04_sr1",
"stations.local.id": "CAS04",
"stations.local.mth5_path": "/home/kkappler/software/irismt/aurora/docs/examples/8P_CAS04.h5",
"stations.local.remote": false,
"stations.local.runs": [
{
"run": {
"id": "b",
"input_channels": [
{
"channel": {
"id": "hx",
"scale_factor": 1.0
}
},
{
"channel": {
"id": "hy",
"scale_factor": 1.0
}
}
],
"output_channels": [
{
"channel": {
"id": "ex",
"scale_factor": 1.0
}
},
{
"channel": {
"id": "ey",
"scale_factor": 1.0
}
},
{
"channel": {
"id": "hz",
"scale_factor": 1.0
}
}
],
"sample_rate": 1.0,
"time_periods": [
{
"time_period": {
"end": "2020-06-12T17:52:23+00:00",
"start": "2020-06-02T22:24:55+00:00"
}
}
]
}
},
{
"run": {
"id": "d",
"input_channels": [
{
"channel": {
"id": "hx",
"scale_factor": 1.0
}
},
{
"channel": {
"id": "hy",
"scale_factor": 1.0
}
}
],
"output_channels": [
{
"channel": {
"id": "ex",
"scale_factor": 1.0
}
},
{
"channel": {
"id": "ey",
"scale_factor": 1.0
}
},
{
"channel": {
"id": "hz",
"scale_factor": 1.0
}
}
],
"sample_rate": 1.0,
"time_periods": [
{
"time_period": {
"end": "2020-07-13T19:00:00+00:00",
"start": "2020-07-01T19:36:55+00:00"
}
}
]
}
}
],
"stations.remote": []
}
}
What if I have unconventional channel names?¶
Aurora uses “ex”, “ey”, “hx”, “hy”, “hz” as default names, but not all MTH5 files will use this nomenclauture. For example, files generated from some Phoenix system call channels “e1”, “e2”, “h1”, “h2”, “h3”
A complete list of supported channel mappings is in mt_metadata/transfer_functions/processing/aurora/standards/channel_nomenclatures.json
Here is an exmaple of how update the config in this case:
[32]:
# config.channel_nomenclature.keyword = "phoenix123"
# config.set_default_input_output_channels()
# config.set_default_reference_channels()
Exercise:¶
Print the processing config by calling config
Modify the nomenclature using the above code, and print it again.
Confirm that the two configs are different. Can you spot the differences?
Run the Aurora Pipeline using the input MTh5 and Confiugration File
[33]:
show_plot = True
tf_cls = process_mth5(config,
kernel_dataset,
units="MT",
show_plot=show_plot,
z_file_path=None,
)
2025-07-11T17:39:04.124863-0700 | INFO | aurora.pipelines.transfer_function_kernel | show_processing_summary | Processing Summary Dataframe:
2025-07-11T17:39:04.130200-0700 | INFO | aurora.pipelines.transfer_function_kernel | show_processing_summary |
duration has_data n_samples run station survey run_hdf5_reference station_hdf5_reference fc remote stft mth5_obj dec_level dec_factor sample_rate window_duration num_samples_window num_samples num_stft_windows
0 847648.0 True 847649 b CAS04 CONUS South <HDF5 object reference> <HDF5 object reference> <NA> False None None 0 1.0 1.000000 128.0 128 847648.0 8829.0
1 847648.0 True 847649 b CAS04 CONUS South <HDF5 object reference> <HDF5 object reference> <NA> False None None 1 4.0 0.250000 512.0 128 211912.0 2207.0
2 847648.0 True 847649 b CAS04 CONUS South <HDF5 object reference> <HDF5 object reference> <NA> False None None 2 4.0 0.062500 2048.0 128 52978.0 551.0
3 847648.0 True 847649 b CAS04 CONUS South <HDF5 object reference> <HDF5 object reference> <NA> False None None 3 4.0 0.015625 8192.0 128 13244.0 137.0
4 1034585.0 True 1034586 d CAS04 CONUS South <HDF5 object reference> <HDF5 object reference> <NA> False None None 0 1.0 1.000000 128.0 128 1034585.0 10776.0
5 1034585.0 True 1034586 d CAS04 CONUS South <HDF5 object reference> <HDF5 object reference> <NA> False None None 1 4.0 0.250000 512.0 128 258646.0 2693.0
6 1034585.0 True 1034586 d CAS04 CONUS South <HDF5 object reference> <HDF5 object reference> <NA> False None None 2 4.0 0.062500 2048.0 128 64661.0 673.0
7 1034585.0 True 1034586 d CAS04 CONUS South <HDF5 object reference> <HDF5 object reference> <NA> False None None 3 4.0 0.015625 8192.0 128 16165.0 168.0
2025-07-11T17:39:04.132196-0700 | INFO | aurora.pipelines.transfer_function_kernel | memory_check | Total memory: 62.74 GB
2025-07-11T17:39:04.133745-0700 | INFO | aurora.pipelines.transfer_function_kernel | memory_check | Total Bytes of Raw Data: 0.014 GB
2025-07-11T17:39:04.134216-0700 | INFO | aurora.pipelines.transfer_function_kernel | memory_check | Raw Data will use: 0.022 % of memory
2025-07-11T17:39:04.145551-0700 | INFO | aurora.pipelines.transfer_function_kernel | mth5_has_fcs | Fourier coefficients not detected for survey: CONUS South, station: CAS04, run: b-- Fourier coefficients will be computed
2025-07-11T17:39:04.290234-0700 | INFO | mth5.mth5 | close_mth5 | Flushing and closing /home/kkappler/software/irismt/aurora/docs/examples/8P_CAS04.h5
2025-07-11T17:39:04.301417-0700 | INFO | aurora.pipelines.transfer_function_kernel | mth5_has_fcs | Fourier coefficients not detected for survey: CONUS South, station: CAS04, run: d-- Fourier coefficients will be computed
2025-07-11T17:39:04.416308-0700 | INFO | mth5.mth5 | close_mth5 | Flushing and closing /home/kkappler/software/irismt/aurora/docs/examples/8P_CAS04.h5
2025-07-11T17:39:04.418028-0700 | INFO | aurora.pipelines.transfer_function_kernel | check_if_fcs_already_exist | FC levels not present
2025-07-11T17:39:04.420113-0700 | INFO | aurora.pipelines.process_mth5 | process_mth5_legacy | Processing config indicates 4 decimation levels
2025-07-11T17:39:04.421453-0700 | INFO | aurora.pipelines.transfer_function_kernel | valid_decimations | After validation there are 4 valid decimation levels
2025-07-11T17:39:06.897331-0700 | INFO | mth5.processing.kernel_dataset | initialize_dataframe_for_processing | Dataset dataframe initialized successfully
2025-07-11T17:39:06.898671-0700 | INFO | aurora.pipelines.transfer_function_kernel | update_dataset_df | Dataset Dataframe Updated for decimation level 0 Successfully
2025-07-11T17:39:08.287010-0700 | INFO | aurora.time_series.spectrogram_helpers | save_fourier_coefficients | Skip saving FCs. dec_level_config.save_fc = False
2025-07-11T17:39:09.684219-0700 | INFO | aurora.time_series.spectrogram_helpers | save_fourier_coefficients | Skip saving FCs. dec_level_config.save_fc = False
2025-07-11T17:39:09.695812-0700 | WARNING | aurora.pipelines.feature_weights | extract_features | Features could not be accessed from MTH5 --
Calculating features on the fly (development only)
2025-07-11T17:39:09.710035-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 25.728968s (0.038867Hz)
2025-07-11T17:39:09.836324-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 19.929573s (0.050177Hz)
2025-07-11T17:39:10.021655-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 15.164131s (0.065945Hz)
2025-07-11T17:39:10.221885-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 11.746086s (0.085135Hz)
2025-07-11T17:39:10.478535-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 9.195791s (0.108745Hz)
2025-07-11T17:39:10.794427-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 7.362526s (0.135823Hz)
2025-07-11T17:39:11.195097-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 5.856115s (0.170762Hz)
2025-07-11T17:39:11.642160-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 4.682492s (0.213562Hz)
2025-07-11T17:39:12.117321-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 25.728968s (0.038867Hz)
2025-07-11T17:39:12.259111-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 19.929573s (0.050177Hz)
2025-07-11T17:39:12.464593-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 15.164131s (0.065945Hz)
2025-07-11T17:39:12.670809-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 11.746086s (0.085135Hz)
2025-07-11T17:39:12.930364-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 9.195791s (0.108745Hz)
2025-07-11T17:39:13.193437-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 7.362526s (0.135823Hz)
2025-07-11T17:39:13.532798-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 5.856115s (0.170762Hz)
2025-07-11T17:39:13.843935-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 4.682492s (0.213562Hz)
2025-07-11T17:39:14.340768-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 25.728968s (0.038867Hz)
2025-07-11T17:39:14.503653-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 19.929573s (0.050177Hz)
2025-07-11T17:39:14.687783-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 15.164131s (0.065945Hz)
2025-07-11T17:39:14.893185-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 11.746086s (0.085135Hz)
2025-07-11T17:39:15.139200-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 9.195791s (0.108745Hz)
2025-07-11T17:39:15.430306-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 7.362526s (0.135823Hz)
2025-07-11T17:39:15.722274-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 5.856115s (0.170762Hz)
2025-07-11T17:39:16.038793-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 4.682492s (0.213562Hz)
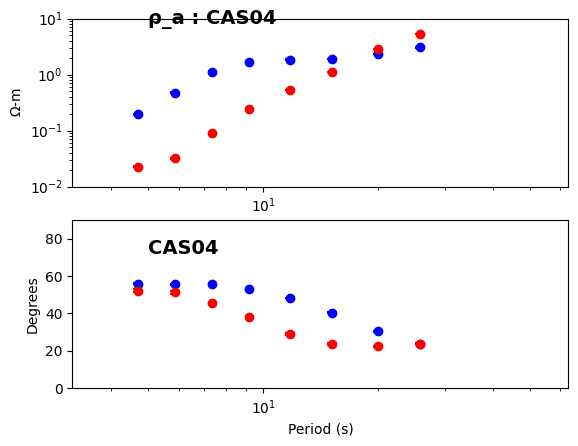
2025-07-11T17:39:17.081456-0700 | INFO | aurora.pipelines.transfer_function_kernel | update_dataset_df | DECIMATION LEVEL 1
2025-07-11T17:39:17.279036-0700 | INFO | aurora.pipelines.transfer_function_kernel | update_dataset_df | Dataset Dataframe Updated for decimation level 1 Successfully
2025-07-11T17:39:17.883669-0700 | INFO | aurora.time_series.spectrogram_helpers | save_fourier_coefficients | Skip saving FCs. dec_level_config.save_fc = False
2025-07-11T17:39:18.406106-0700 | INFO | aurora.time_series.spectrogram_helpers | save_fourier_coefficients | Skip saving FCs. dec_level_config.save_fc = False
2025-07-11T17:39:18.412128-0700 | WARNING | aurora.pipelines.feature_weights | extract_features | Features could not be accessed from MTH5 --
Calculating features on the fly (development only)
2025-07-11T17:39:18.419603-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 102.915872s (0.009717Hz)
2025-07-11T17:39:18.472637-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 85.631182s (0.011678Hz)
2025-07-11T17:39:18.554829-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 68.881694s (0.014518Hz)
2025-07-11T17:39:18.652110-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 54.195827s (0.018452Hz)
2025-07-11T17:39:18.750223-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 43.003958s (0.023254Hz)
2025-07-11T17:39:18.858432-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 33.310722s (0.030020Hz)
2025-07-11T17:39:18.987259-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 102.915872s (0.009717Hz)
2025-07-11T17:39:19.075505-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 85.631182s (0.011678Hz)
2025-07-11T17:39:19.157763-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 68.881694s (0.014518Hz)
2025-07-11T17:39:19.256440-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 54.195827s (0.018452Hz)
2025-07-11T17:39:19.354031-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 43.003958s (0.023254Hz)
2025-07-11T17:39:19.460390-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 33.310722s (0.030020Hz)
2025-07-11T17:39:19.621506-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 102.915872s (0.009717Hz)
2025-07-11T17:39:19.726024-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 85.631182s (0.011678Hz)
2025-07-11T17:39:19.813092-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 68.881694s (0.014518Hz)
2025-07-11T17:39:19.912741-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 54.195827s (0.018452Hz)
2025-07-11T17:39:20.021794-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 43.003958s (0.023254Hz)
2025-07-11T17:39:20.142141-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 33.310722s (0.030020Hz)
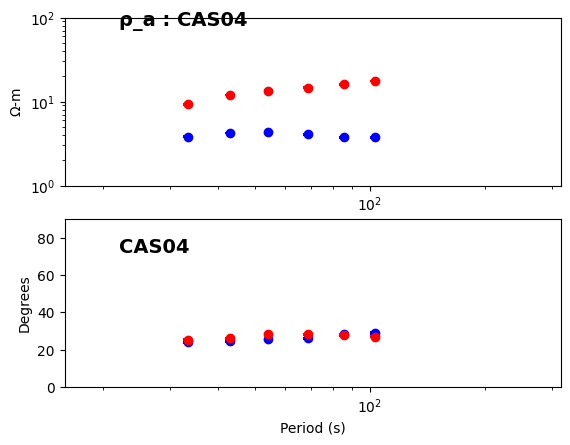
2025-07-11T17:39:20.776612-0700 | INFO | aurora.pipelines.transfer_function_kernel | update_dataset_df | DECIMATION LEVEL 2
2025-07-11T17:39:20.851477-0700 | INFO | aurora.pipelines.transfer_function_kernel | update_dataset_df | Dataset Dataframe Updated for decimation level 2 Successfully
2025-07-11T17:39:21.227456-0700 | INFO | aurora.time_series.spectrogram_helpers | save_fourier_coefficients | Skip saving FCs. dec_level_config.save_fc = False
2025-07-11T17:39:21.530786-0700 | INFO | aurora.time_series.spectrogram_helpers | save_fourier_coefficients | Skip saving FCs. dec_level_config.save_fc = False
2025-07-11T17:39:21.534637-0700 | WARNING | aurora.pipelines.feature_weights | extract_features | Features could not be accessed from MTH5 --
Calculating features on the fly (development only)
2025-07-11T17:39:21.545095-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 411.663489s (0.002429Hz)
2025-07-11T17:39:21.571250-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 342.524727s (0.002919Hz)
2025-07-11T17:39:21.601020-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 275.526776s (0.003629Hz)
2025-07-11T17:39:21.646823-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 216.783308s (0.004613Hz)
2025-07-11T17:39:21.729840-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 172.015831s (0.005813Hz)
2025-07-11T17:39:21.821838-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 133.242890s (0.007505Hz)
2025-07-11T17:39:21.977956-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 411.663489s (0.002429Hz)
2025-07-11T17:39:22.073634-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 342.524727s (0.002919Hz)
2025-07-11T17:39:22.104439-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 275.526776s (0.003629Hz)
2025-07-11T17:39:22.147826-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 216.783308s (0.004613Hz)
2025-07-11T17:39:22.227662-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 172.015831s (0.005813Hz)
2025-07-11T17:39:22.313085-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 133.242890s (0.007505Hz)
2025-07-11T17:39:22.406633-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 411.663489s (0.002429Hz)
2025-07-11T17:39:22.469859-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 342.524727s (0.002919Hz)
2025-07-11T17:39:22.499366-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 275.526776s (0.003629Hz)
2025-07-11T17:39:22.543015-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 216.783308s (0.004613Hz)
2025-07-11T17:39:22.618067-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 172.015831s (0.005813Hz)
2025-07-11T17:39:22.714298-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 133.242890s (0.007505Hz)
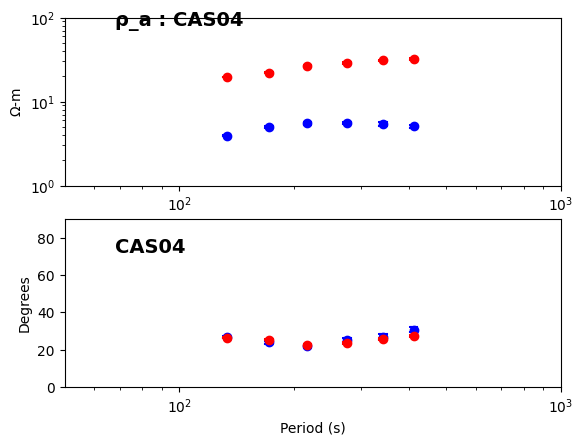
2025-07-11T17:39:23.259964-0700 | INFO | aurora.pipelines.transfer_function_kernel | update_dataset_df | DECIMATION LEVEL 3
2025-07-11T17:39:23.290801-0700 | INFO | aurora.pipelines.transfer_function_kernel | update_dataset_df | Dataset Dataframe Updated for decimation level 3 Successfully
2025-07-11T17:39:23.568881-0700 | INFO | aurora.time_series.spectrogram_helpers | save_fourier_coefficients | Skip saving FCs. dec_level_config.save_fc = False
2025-07-11T17:39:23.786675-0700 | INFO | aurora.time_series.spectrogram_helpers | save_fourier_coefficients | Skip saving FCs. dec_level_config.save_fc = False
2025-07-11T17:39:23.789638-0700 | WARNING | aurora.pipelines.feature_weights | extract_features | Features could not be accessed from MTH5 --
Calculating features on the fly (development only)
2025-07-11T17:39:23.796944-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 1514.701336s (0.000660Hz)
2025-07-11T17:39:23.821246-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 1042.488956s (0.000959Hz)
2025-07-11T17:39:23.847033-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 723.371271s (0.001382Hz)
2025-07-11T17:39:23.874233-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 532.971560s (0.001876Hz)
2025-07-11T17:39:23.898372-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 412.837995s (0.002422Hz)
2025-07-11T17:39:23.928249-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 1514.701336s (0.000660Hz)
2025-07-11T17:39:23.955901-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 1042.488956s (0.000959Hz)
2025-07-11T17:39:23.984639-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 723.371271s (0.001382Hz)
2025-07-11T17:39:24.019940-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 532.971560s (0.001876Hz)
2025-07-11T17:39:24.052375-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 412.837995s (0.002422Hz)
2025-07-11T17:39:24.090261-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 1514.701336s (0.000660Hz)
2025-07-11T17:39:24.118385-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 1042.488956s (0.000959Hz)
2025-07-11T17:39:24.159490-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 723.371271s (0.001382Hz)
2025-07-11T17:39:24.197207-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 532.971560s (0.001876Hz)
2025-07-11T17:39:24.235168-0700 | INFO | aurora.time_series.frequency_band_helpers | get_band_for_tf_estimate | Accessing band 412.837995s (0.002422Hz)
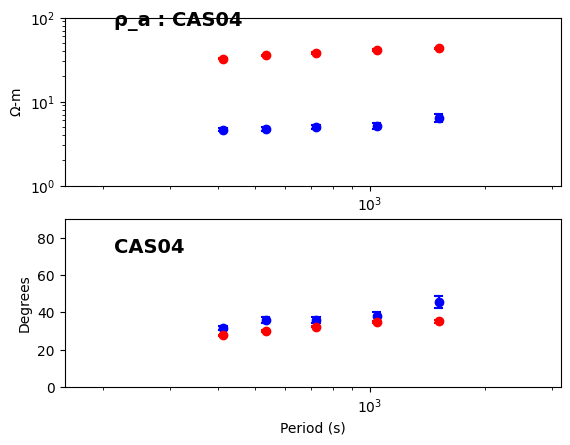
2025-07-11T17:39:25.068677-0700 | INFO | mth5.mth5 | close_mth5 | Flushing and closing /home/kkappler/software/irismt/aurora/docs/examples/8P_CAS04.h5
[34]:
type(tf_cls)
[34]:
mt_metadata.transfer_functions.core.TF
Write the transfer functions generated by the Aurora pipeline
[35]:
tf_cls.write(fn="emtfxml_test.xml", file_type="emtfxml")
[35]:
EMTFXML(station='0', latitude=0.00, longitude=0.00, elevation=0.00)
[36]:
tf_cls.write(fn="emtfxml_test.edi", file_type="edi")
[36]:
Station: 0
--------------------------------------------------
Survey: 0
Project: None
Acquired by: None
Acquired date: 1980-01-01
Latitude: 0.000
Longitude: 0.000
Elevation: 0.000
Impedance: True
Tipper: True
Number of periods: 25
Period Range: 4.68249E+00 -- 1.51470E+03 s
Frequency Range 6.60196E-04 -- 2.13561E-01 s
[37]:
tf_cls.write(fn="emtfxml_test.zss", file_type="zmm")
[37]:
MT( station='0', latitude=0.00, longitude=0.00, elevation=0.00 )
[ ]: